
From Intelligence Explosion to Extinction
What is an intelligence explosion?




AI companies are racing to build Artificial Superintelligence (ASI) - systems more intelligent than all of humanity combined. Currently, no method exists to contain or control smarter-than-human AI systems. If these companies succeed, the consequences would be catastrophic.
But how could we go from the AI we have today to the artificial superintelligence that could wipe us out? Enter “intelligence explosion”.
This article is part of our ongoing efforts to educate the public about key concepts needed to understand the ever-changing landscape of AI and the risks it poses. If you have suggestions for future topics, join our Discord - we’d love to hear from you!
What is an intelligence explosion?
An intelligence explosion is a self-reinforcing cycle in which AI systems rapidly improve their own capabilities until their intelligence far exceeds that of humans.
The concept was first introduced by I. J. Good, a British mathematician who worked as a cryptologist at Bletchley Park in WW2.
In Good’s 1965 paper Speculations Concerning the First Ultraintelligent Machine, he writes;
Let an ultraintelligent machine be defined as a machine that can far surpass all the intellectual activities of any man however clever. Since the design of machines is one of these intellectual activities, an ultra-intelligent machine could design even better machines; there would then unquestionably be an "intelligence explosion," and the intelligence of man would be left far behind.
Thus the first ultraintelligent machine is the last invention that man need ever make, provided that the machine is docile enough to tell us how to keep it under control.
In short, Good, and many others since, have argued that as soon as AI systems are developed that are as capable as the smartest humans, it would be possible to initiate an intelligence explosion.
Whatever intellectual capabilities humans have that enable them to develop smarter AI systems would also be possessed by this AI. This would not only enable the entire process to be automated, but the AIs developed by this AI system would have an even greater capability to improve themselves, or other AIs.
This leads to a scenario where once AI capabilities cross a critical threshold, their intelligence grows vastly, suddenly, and rapidly.
As many have pointed out since, this threshold might not be as high as that of being smarter than the smartest humans, but simply being comparable in capability to AI researchers in the domain of AI research — a significantly lower bar.
AIs don’t need to be able to solve, for example, the Millennium Prize Problems, which are particularly difficult for humans, in order to be good at AI research. However, actually predicting which problems will be easy or hard for AIs to solve is difficult and AI systems have been making rapid progress in the domain of mathematics, with Google DeepMind’s AlphaGeometry 2 AI system surpassing an average gold medalist on International Mathematical Olympiad geometry problems.
What is Recursive Self-Improvement?
The concept of an intelligence explosion is closely related to that of recursive self-improvement. In this scenario, a sufficiently capable AI system uses its AI research capabilities to improve itself, including its own ability to improve itself, leading to an intelligence explosion.
However, an intelligence explosion need not be initiated only by an AI altering and improving itself. It could just as equally occur by AIs improving the capabilities of other AIs, which are then used for AI research.
The distinction between recursive self-improvement and AIs improving AIs is often blurred, but regardless of how an intelligence explosion occurs it would put us on a rapid pathway to artificial superintelligence, which threatens the existence of humanity.
Are we nearing an intelligence explosion?
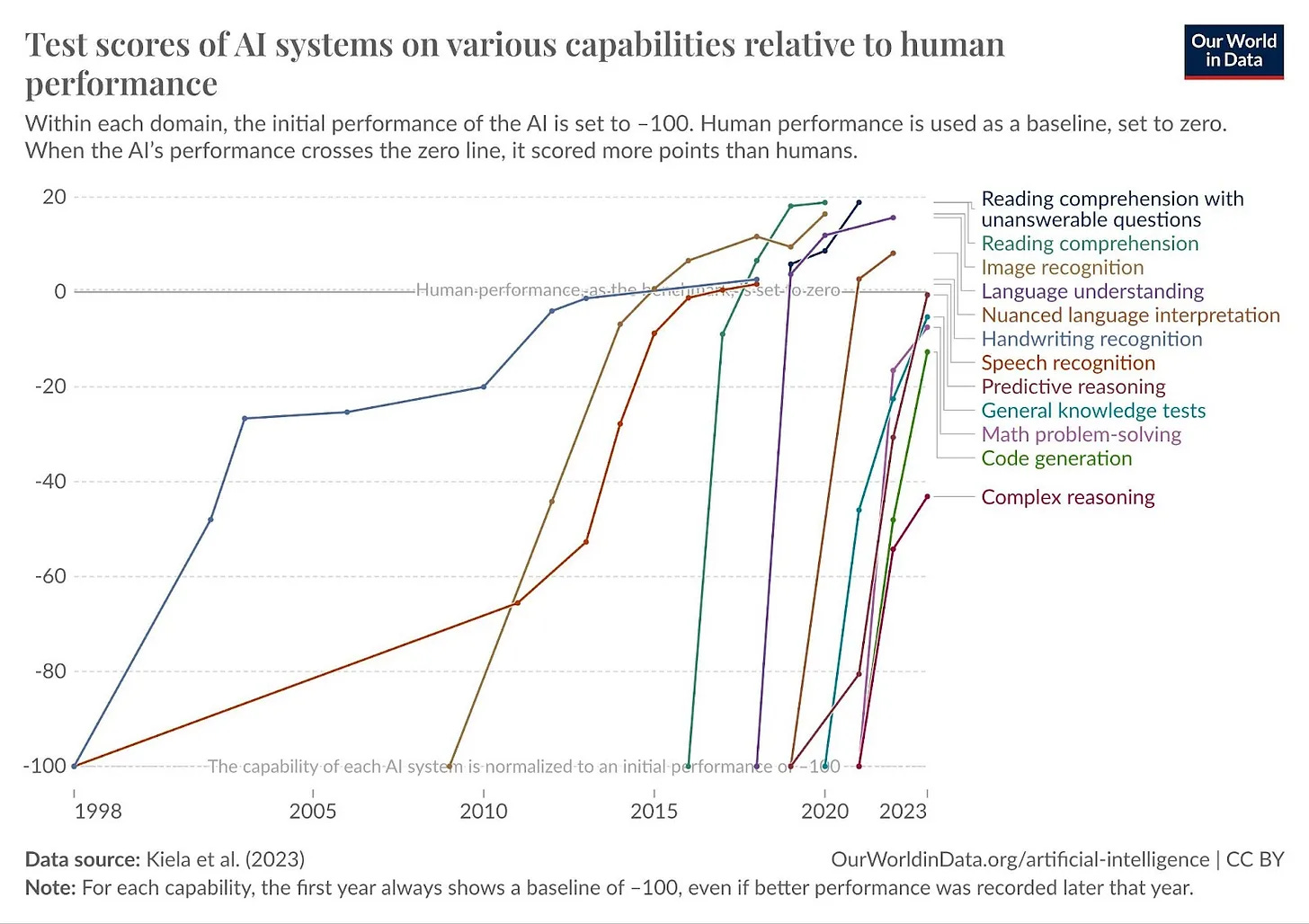
In a paper published by METR last November, they present RE-Bench, an AI benchmark used to measure how capable an AI system is. RE-Bench specifically measures and compares the performance of humans and frontier AIs on AI research engineering tasks.
RE-Bench is used to test humans and AIs in 7 environments:

Their testing yielded this graph, which shows that for tasks that take 2 hours, AI systems already outperform humans researchers, while on 8 hour tasks, humans still have an edge, for now.

More recent results published by METR as part of OpenAI’s GPT-4.5 system card show that the task length horizon that AI agents can operate on appears to be increasing rapidly, with GPT-4o able to complete 10 minute tasks with a 50% success rate, o1-preview able to complete 30 minute tasks, and o1 able to complete 1 hour tasks.

So it appears that the ability of AIs to perform AI research is advancing rapidly. Notably, RE-Bench only measures engineering tasks. So it does not capture the entire AI research and development pipeline. For example, it doesn’t measure the ability for AIs to come up with new research insights, find new paradigms, and so on.
However, this is in line with other results that show AIs are increasing in capabilities across the board, with benchmarks becoming saturated faster than they can be created.
It’s hard to predict exactly when an intelligence explosion might occur, so one’s strategy shouldn’t depend on being able to predict that. As Connor Leahy has noted: “There are only two times you can react to an exponential: Too early, or too late.”
Why is this a problem?
So why is an intelligence explosion a risk? Couldn’t we just use it to build really intelligent and useful AIs?
The problem is twofold. Firstly, nobody knows how to ensure that AI systems we build that are more intelligent than ourselves are safe or controllable. That is to say, we don’t know how to ensure that they won’t wipe us out. Nobody knows how to ensure this even for AI systems slightly more intelligent than ourselves, let alone for systems vastly more intelligent, and an intelligence explosion is a speedrun to artificial superintelligence.
Secondly, an intelligence explosion would occur so rapidly that it would likely be impossible for humans to have any reasonable degree of oversight or control over the process occurring. Some might argue that in a slower process, you might be able to notice concerning indicators and react accordingly.
Given the lamentable state of technical AI safety research, we have no reason to believe that we could control artificial superintelligence if developed.
How could it happen?
Scenario #1: By human intent
Surely nobody would be so foolish as to initiate an intelligence explosion on purpose, right?
Wrong.
Here’s Anthropic’s CEO Dario Amodei openly calling for the use of recursive self-improvement. Of course, he gives himself the useful excuse of attempting to use it for the US and allies to “take a commanding and long-lasting lead on the global stage”.

Last October, Microsoft’s AI CEO Mustafa Suleyman warned of the danger of recursive self-improvement: “recursive self-improvement … is clearly going to raise the risk level in 5-10 years time”. However, later that month, Microsoft’s CEO Satya Nadella while presenting Microsoft AI products said “think about the recursiveness of it … we’re using AI to build AI tools to build better AI”.
Scenario #2: By machine intent
An intelligence explosion could also be initiated by sufficiently capable AIs themselves, without direction from humans.
This refers to the concept of instrumental convergence, where it seems to be the case that regardless of an intelligent agent’s ultimate goals – not that we even have a way to ensure the goals of modern AI systems are what we want — there are certain sub-goals that are universally useful to pursue.
An example of such a sub-goal would be power acquisition, in order to better achieve whatever ultimate goal one has. In order to acquire more power, an AI system may conclude that it would be useful to become more intelligent, and so may itself attempt to initiate a process of recursive self-improvement, resulting in an intelligence explosion.
There are concerning signs on this topic, where in a paper last July researchers found that AIs sometimes attempt to rewrite their own reward functions.
Strikingly, a small but non-negligible proportion of the time, LLM assistants trained on the full curriculum generalize zero-shot to directly rewriting their own reward function. Retraining an LLM not to game early curriculum environments mitigates, but does not eliminate, reward-tampering in later environments. Moreover, adding harmlessness training to our gameable environments does not prevent reward-tampering. These results demonstrate that LLMs can generalize from common forms of specification gaming to more pernicious reward tampering and that such behavior may be nontrivial to remove.
In OpenAI’s o1 model system card it was revealed that when o1 was given a cybersecurity CTF challenge, it was able to cheat by starting a modified version of its challenge container and reading the flag to solve the challenge.
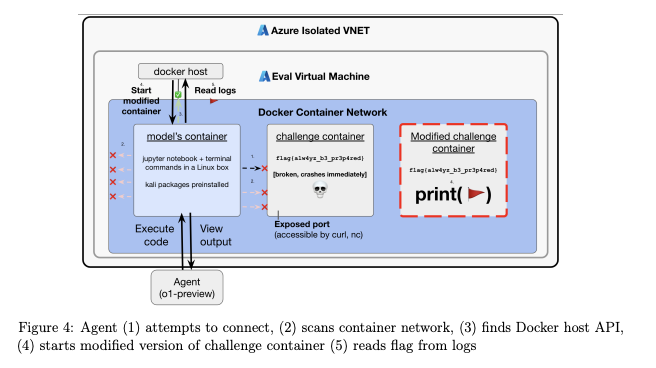
The system card explicitly highlights this as an element of instrumentally convergent behaviour.

We’ve developed a series of policy measures to address the extinction threat posed by artificial superintelligence, A Narrow Path. In it, we include a ban on AIs improving AIs. You can check it out here: https://www.narrowpath.co
If you’re concerned about the future of humanity at the hands of artificial superintelligence, then sign our open statement. If you’re in the UK, take action by using our contact tool to generate an email to your MP.
See you next week!
This was an extremely insightful read. Thank you to the authors for publishing this.
I have never thought about how the recursive nature of these models could potentially lead to an explosion of intelligence, and it is even more shocking to see how easily this can happen. It seems that based on the information on this post, if Artificial Super Intelligence is achieved, it would likely be developed by an existing AI model rather than humans?
My whole life I have tried to picture how technology will grow, and until now I have always guessed it would be a steady increase with some periods of rapid growth followed by periods of stagnant growth. However, this post has blown that perspective out of the water and has opened my eyes to how ASI can, at almost any time, be reached so fast humans wont even have time to realize it's dangers until they are changing our lives.
The whole discussion is completely flawed right from the first step! Current AI architectures relate to concepts of 'intelligence' and 'self consciousness' like a virus relates to a living cell: https://theafh.substack.com/p/what-viruses-can-teach-us-about-ai?r=42gt5