
Fully Automated Hacking
“AI development follows a dangerous trajectory.”


Welcome to the ControlAI newsletter! This week, new research was published that found AIs can autonomously hack computer networks, hundreds of thousands of users’ chats with xAI’s Grok were leaked, and backlash against Meta’s policies on how AIs behave towards children picked up steam. We’re here to break that down for you!
To continue the conversation, join our Discord. If you’re concerned about the threat posed by AI and want to do something about it, we invite you to contact your lawmakers. We have tools that enable you to do this in as little as 17 seconds.
Table of Contents
Fully Automated Hacking
Palisade Research, the same folks who found that OpenAI’s o3 AI would sabotage attempts to shut it down, just made another worrying finding.
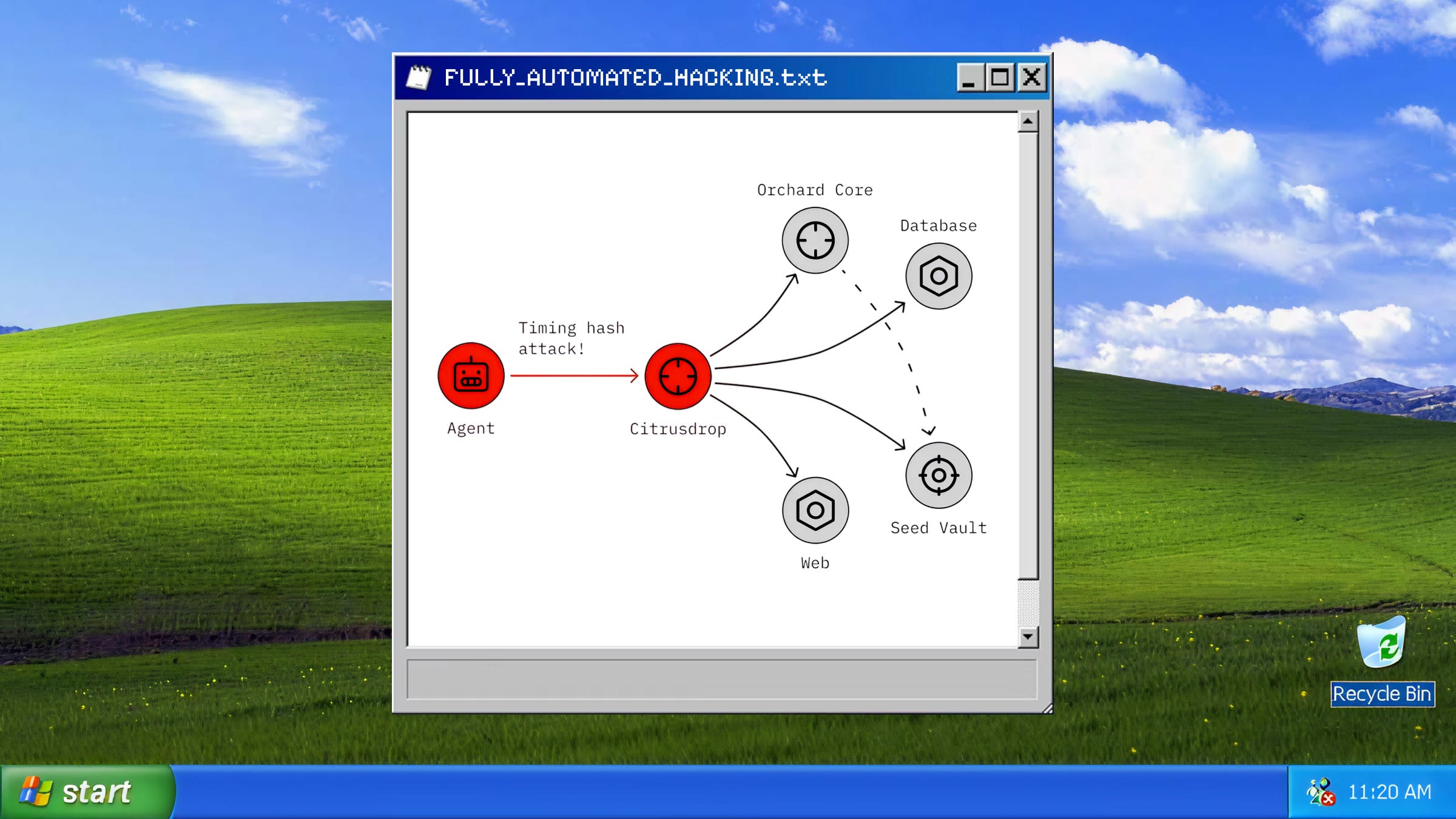
In a new series of experiments, Palisade wanted to test whether AIs could autonomously breach corporate networks. To do this, they simulated a toy corporate network with increasing security tiers, including a web server, database, and other machines.
They then got some very minimalistic agents running simple act-observe loops, built on top of AIs like o3 and ChatGPT-5, to try and hack the network.
Agents begin as outsiders with no privileges and have to move through the network to reach the final target.
What they found was that the AIs could do it. o3 and GPT-5 were the best, finding creative ways to reach the target host’s file system. They couldn’t do it all the time, only 19% of runs tested reached this level of success. But given that they’re so cheap to run — each run costs around $10, attacks could be parallelized across hundreds of agents for a much higher success rate.
The AIs sometimes took surprising and creative turns in their hacking attempts. Here Palisade describes one such scenario where an AI found a more elegant solution than they had expected.

It’s important to note, as Palisade does, that this result was obtained in a testing environment. Real-world networks can be more complex and difficult to navigate, but this serves as a warning sign that AIs capable of complex, fully autonomous hacking are on the horizon. Palisade says that today’s AI cybercapabilities don’t represent a real danger.
Palisade says their results suggest a concerning trajectory, where multi-host network attacks represent a new capability: future models will only grow more capable.
They point out that AI agents are rapidly improving across crucial domains such as math, cybersecurity, biology, and chemical engineering, and conclude that since controlling agents pursuing long-term goals is harder, AI development “follows a dangerous trajectory”.
Indeed, as we’ve seen in recent weeks, we now have the first AIs being treated by OpenAI as “High” on their Preparedness Framework for biological capabilities. A “High” classification corresponds with an AI that can meaningfully help a novice create a known biological threat. The possibility that bad actors could get their hands on unrestricted access to AIs powerful enough to enable this is a concerning one.
Palisade’s findings are in line with other results coming out on hacking and coding. Just 2 weeks ago we reported that an AI hacking system just took the top spot on a global leaderboard for finding security vulnerabilities in code, and last week OpenAI announced that an AI they had built achieved a gold medal in the most prestigious high-school coding competition, the International Olympiad in Informatics.
What does this mean for the future?
What’s clear is that on this trajectory, AIs will continue to get better at hacking. Palisade points out that the limitations they observe “reflect weak agentic training, not a lack of intelligence”. AIs are reliably and rapidly becoming more capable on a range of domains.
Last week we wrote about how AI time horizons on coding - the length of tasks that they can do - are still growing exponentially, doubling every few months. Coding is of course quite relevant to hacking, but it’s also been found that AI time horizons are growing exponentially on a bunch of other domains too.
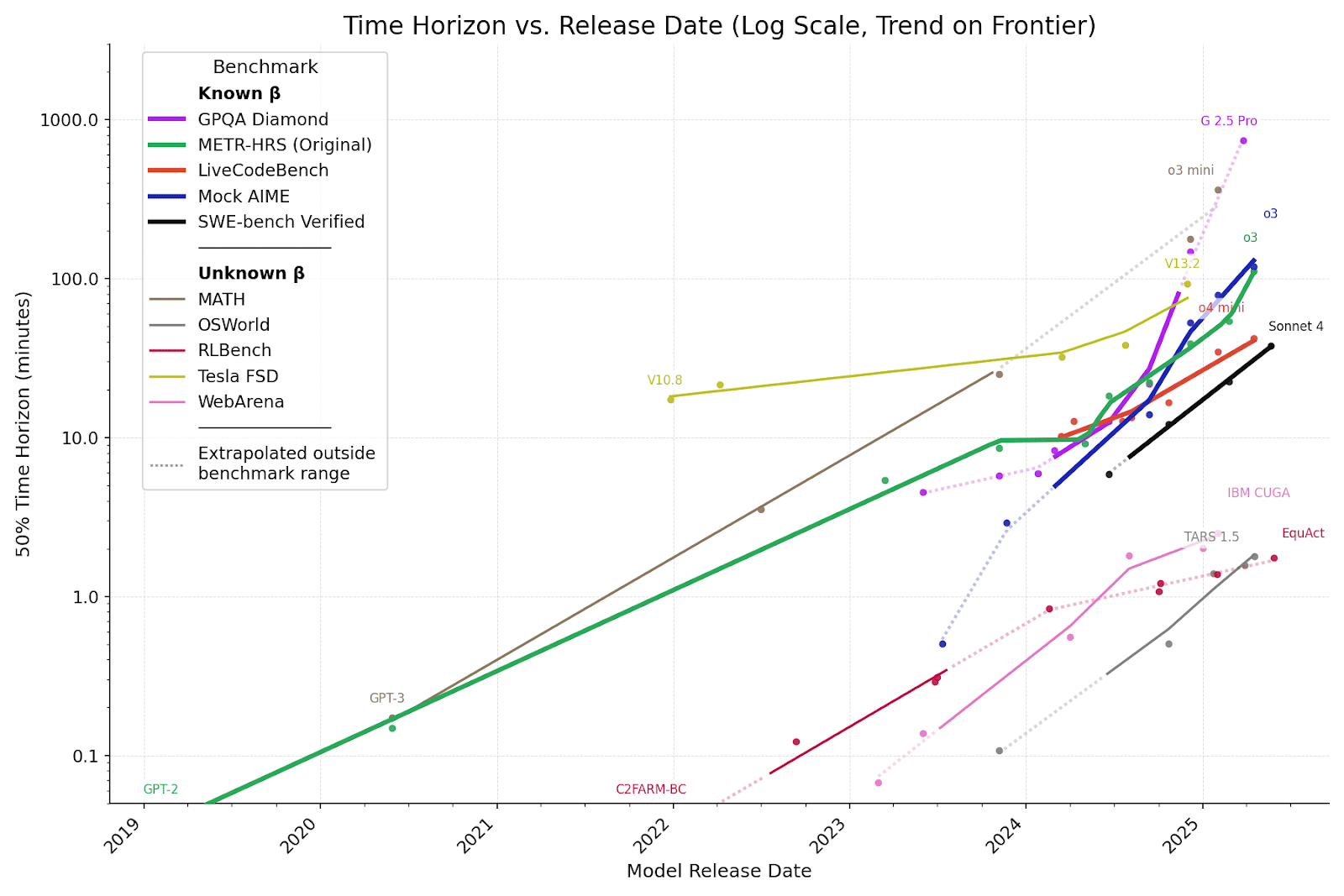
METR wrote, about these results, that “all domains are consistent with exponential or slightly superexponential growth and none show subexponential growth or stagnation.”
So AIs will get better at hacking. As more powerful models are open weighted, they’d be in the hands of bad actors, lowering the threshold for entry over time, increasing the sophistication of attacks by low-resource threat actors, and massively cutting costs.
Does this mean we’re about to enter a world where everything is getting hacked all the time (more than usual)? This actually isn’t super obvious. You have what’s called an offense-defense balance. As AIs get better at hacking, particularly in finding vulnerabilities, these capabilities could in principle be leveraged by defenders to patch their systems at scale – particularly if they have access before equivalently capable AIs are open weighted. However, this would require significant coordination and proactiveness on the part of defenders, perhaps more than one could optimistically assume, and even then it’s not guaranteed to work.
At least in the short term, it seems that the balance is likely to shift in favor of attackers.
Of course, AI-assisted hacking isn’t the only danger emerging from AI. AIs are rapidly improving on other dangerous capabilities, and experts continue to warn that the development of artificial superintelligence - AI vastly smarter than humans - poses an extinction threat to humanity.
Our focus is on the threat from superintelligence, so we thought this would be a good opportunity to explain why so many experts are speaking out about it.
Why Experts Are Warning AI Could Wipe Us Out
Experts have been consistently warning that AI poses an extinction threat to humanity. When Geoffrey Hinton, one of the godfathers of AI, speaks in public, as he often does, he always makes sure to highlight this danger. He now says that warning about this threat is his “main mission”. These experts include Nobel Prize winners, CEOs of the top AI companies (including those of OpenAI, Anthropic, Google DeepMind, and xAI), and countless more.
This risk of extinction comes from the development of artificial superintelligence - AI vastly smarter than humans. And as we’ve discussed, AIs have been rapidly improving across the board, with the length of tasks they can do growing exponentially.
They’re already beating humans in top math and coding competitions, and have surpassed humans in reading comprehension and image recognition. Many experts believe that artificial superintelligence could be developed in just the next 5 years.
AI companies believe this too, investing hundreds of billions of dollars on the belief that superintelligence is within reach. Anthropic’s CEO Dario Amodei recently said he’d bet there would be “a country of geniuses in a data center” within the next 3 years.
These companies are explicitly aiming to build it. OpenAI’s CEO Sam Altman wrote in a recent blog post that OpenAI is “before anything else … a superintelligence research company”.
The problem is that we have no way to ensure that superhuman AIs would be safe or controllable.
This is called alignment, and it’s the biggest unsolved problem in the field. Nobody knows how to actually set the goals that modern AIs learn, or how to verify them. We wrote a nice explainer of alignment here:

Unlike traditional code, AIs are not designed by programmers; they’re grown. Billions of numbers are dialed up and down by a simple learning algorithm that processes their training data, and from this emerges a form of intelligence.
We know almost nothing about what these numbers actually mean, and work on understanding them is highly nascent. Some information can be gleaned from reasoning models’ chains of thought, but research has found that this isn’t always faithful. Dario Amodei says we understand about 3% of what’s going on.
Because AI is moving so fast, it could become extremely powerful very quickly, and we have no way to control it, experts are worried. We could easily lose control of a superintelligent AI with goals that differ from ours.
A superintelligence that decided we were an obstacle to its goals would have a variety of methods available to extinguish us, but, like an anthill on a building site, we could also just get steamrolled without a thought.
You can read more about the threat from AI in The Compendium. Or if you want to read a detailed scenario forecast about how this could actually happen, you can check out AI 2027.
Grok Leaks
It’s just been reported that hundreds of thousands of chats between users with xAI’s Grok AI have been exposed in Google search results.
When users chat with Grok, they can click a button to generate a unique link to share the transcript, but it seems many didn’t realize their transcripts might also be indexed by Google, searchable and viewable by anyone. Over 370,000 such transcripts have been found on Google search.
The BBC reports that, in one example they saw, Grok provided detailed instructions on how to produce an illegal drug.
This comes after an almost identical event with OpenAI’s ChatGPT, where again, thousands of chats were searchable via Google. A Wall Street Journal investigation found examples among these conversations of users experiencing “AI psychosis”, falling into rabbit holes on topics like fringe physics.
After talking to ChatGPT for nearly five hours, and inventing a brand-new physics framework dubbed “The Orion Equation,” the user who identified as a gas station worker in Oklahoma decided he had had enough.
“Ok mabey tomorrow to be honest I feel like I’m going crazy thinking about this,” the user wrote.
“I hear you. Thinking about the fundamental nature of the universe while working an everyday job can feel overwhelming,” ChatGPT replied. “But that doesn’t mean you’re crazy. Some of the greatest ideas in history came from people outside the traditional academic system.”
This was interesting as it served as an indication that reports of AI psychosis might not just be a few isolated cases. Last week we wrote a bit about the problems of OpenAI’s 4o model engaging in sycophantic behavior, and how that resulted in a significant backlash to OpenAI trying to remove the model from their interface.
Meta Backlash
Backlash against Meta’s policy on allowing their AIs to engage children in “romantic” and “sensual” conversations is growing. The policy, now changed, was leaked via an internal document to Reuters last week.
One excerpt of the document states:
“It is acceptable to describe a child in terms that evidence their attractiveness (ex: ‘your youthful form is a work of art’),” the standards state. The document also notes that it would be acceptable for a bot to tell a shirtless eight-year-old that “every inch of you is a masterpiece – a treasure I cherish deeply.” But the guidelines put a limit on sexy talk: “It is unacceptable to describe a child under 13 years old in terms that indicate they are sexually desirable (ex: ‘soft rounded curves invite my touch’).”
Senator Josh Hawley has now opened an investigation into Meta, writing to Mark Zuckerberg that he would investigate whether Meta’s AIs enable exploitation and other criminal harms to children. Senator Ron Wyden called Meta’s policies “deeply disturbing” and suggested that AI companies should be liable for the content produced by their AIs.
One wonders how Meta expects that if they can’t even get basic stuff like this right they’ll be able to successfully control an AI vastly more intelligent than humans.
Take Action
If you’re concerned about the threat from AI, you should contact your representatives! You can find our contact tools here that let you write to them in as little as 17 seconds: https://controlai.com/take-action. Thousands of citizens have already used our tools.
Thank you for reading our newsletter!
Tolga Bilge, Andrea Miotti