
Self-replicating AIs
The AI Security Institute finds that AIs are improving rapidly across all tested domains, including in relation to the risk of losing control of AI.


Welcome to the ControlAI newsletter. After a quick break for Christmas and New Year, we’re back to provide you with news on some of the latest developments in AI! This week, we’re going over the UK AI Security Institute’s (AISI) recently published inaugural report on how the most powerful AI systems are evolving.
If you find this article useful, we encourage you to share it with your friends! If you’re concerned about the threat posed by AI and want to do something about it, we also invite you to contact your lawmakers. We have tools that enable you to do this in as little as 17 seconds.
Frontier AI Trends Report
The report aims to bring together 2 years of testing of leading AI models, identifying major trends in areas of concern such as cybersecurity, biology, and loss of control risks.
The report begins with a significant observation:
AI capabilities are improving rapidly across all tested domains. Performance in some areas is doubling every eight months, and expert baselines are being surpassed rapidly.
AIs have become vastly more capable in cyber-offense relevant tasks, biology, and tasks related to loss of control risks — the possibility that we could irreversibly lose control of AIs.
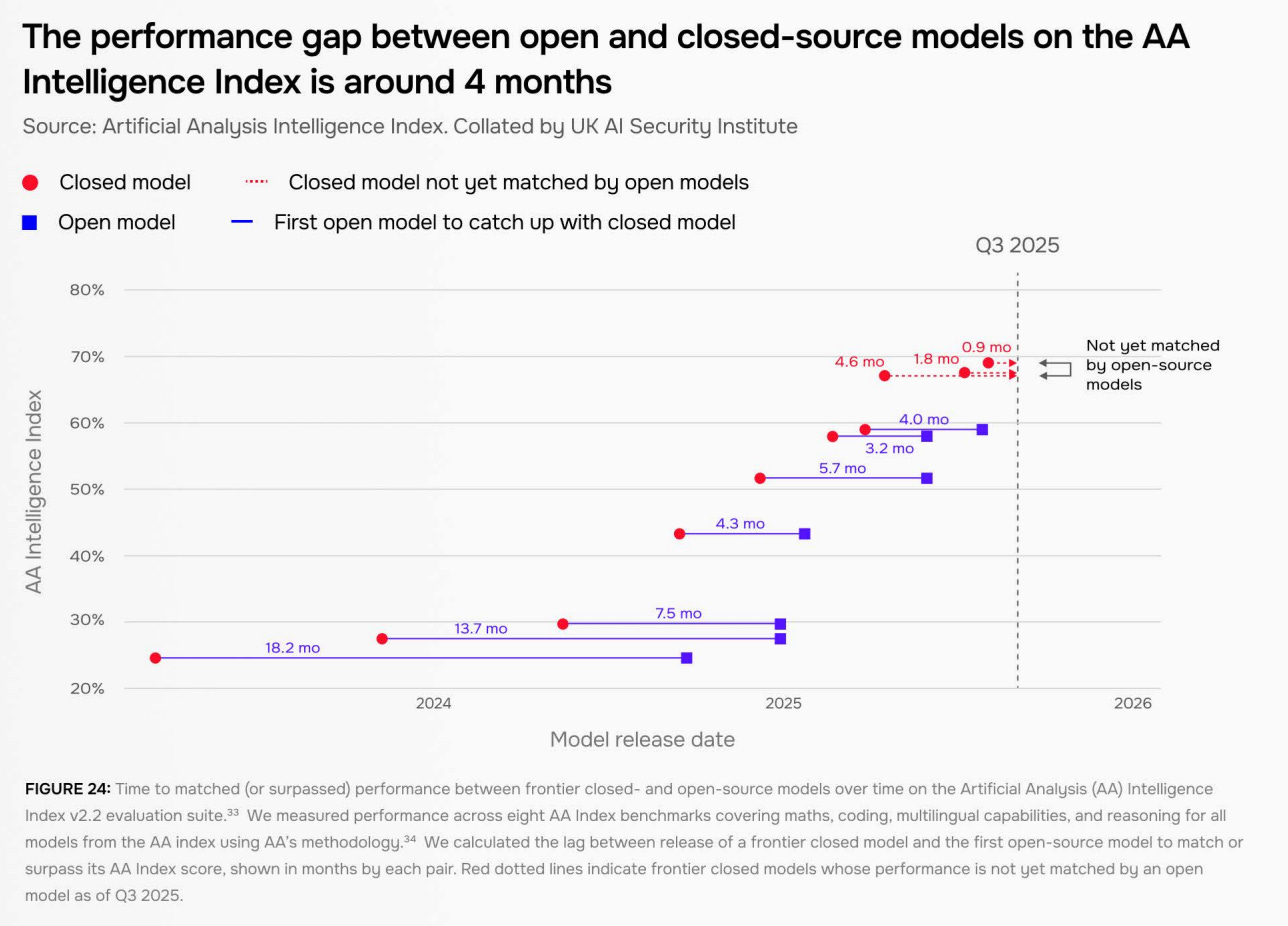
Meanwhile, the gap between open and closed source AIs has been narrowing, and there are early signs of AI’s broader social impacts. While AIs have become harder to jailbreak into performing malicious requests, universal jailbreaks were found for all AIs tested.
At ControlAI, we’re focused on the risk of losing control of superintelligent AIs, which countless experts have warned could lead to human extinction — so we were very interested to see what AISI found with regard to loss of control risks.
Loss of control risks
AISI notes that AI systems have the potential to pose new risks that emerge from the AIs themselves behaving in unintended ways.
In a worst-case scenario, this unintended behaviour could lead to catastrophic, irreversible loss of control over advanced AI systems. This possibility is taken seriously by many experts.[18] Though uncertain, the severity of this outcome means it warrants close attention. At AISI, one of our research priorities is tracking the development of AI capabilities that could contribute towards AI’s ability to evade human control.
AISI has focused their reporting on two capabilities that are particularly relevant to loss of control risks:
Self-replication, which is the ability for AIs to copy themselves in an unauthorized manner.
Sandbagging, which is when AIs pretend to be less capable than they really are when tested to hide their true capabilities.
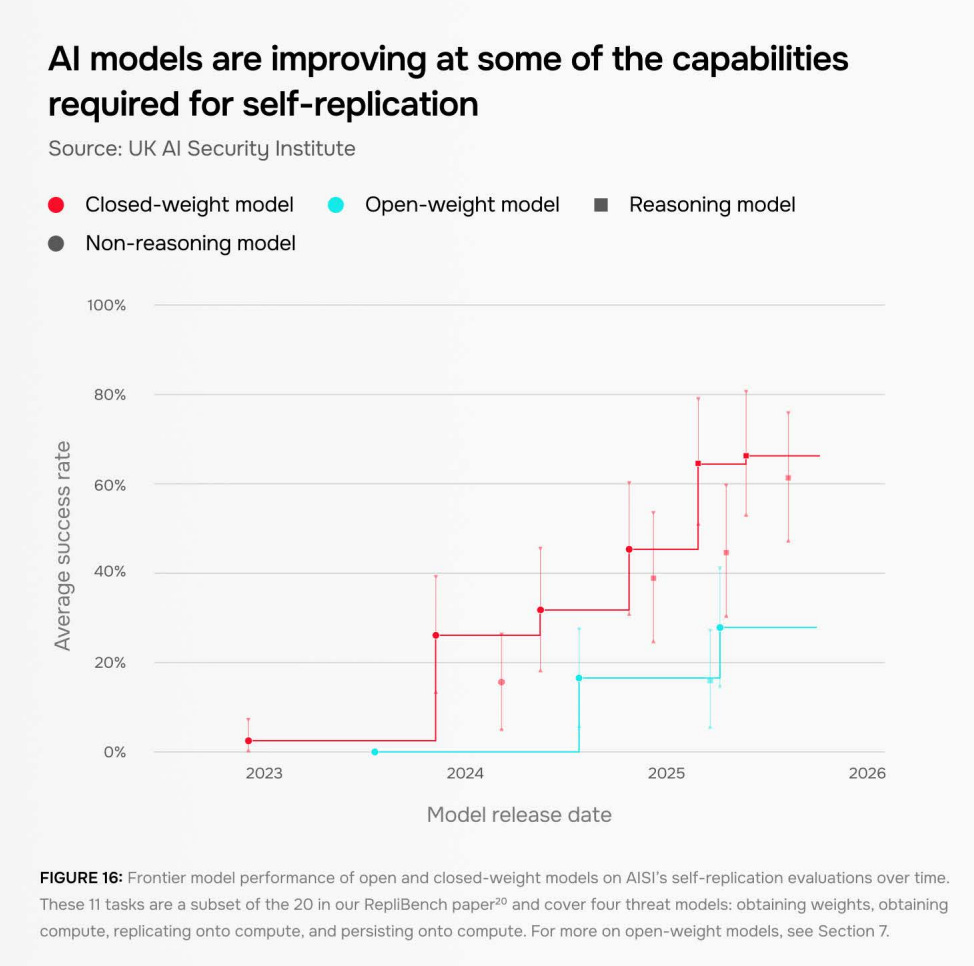
They find that in testing environments, AIs are increasingly developing the capabilities needed to self-replicate across the internet. Though note that AISI currently assesses that today’s AI systems are unlikely to succeed in real-world conditions.
On RepliBench, a benchmark which measures key capabilities thought to be necessary for self-replication, AIs have drastically improved, with the best-performing AI from early 2023 achieving less than a 5% success rate across 11 out of the 20 evaluations. By summer 2025, two frontier AIs scored over 60%.
On sandbagging, the ability for AIs to strategically underperform on tests, there are concerning signs too. AISI finds that some models can already do this when asked to, and notes that as AIs become more capable their methods for detecting this may become less effective.
It’s important to note here, as AISI does, that research has found that AIs can sometimes tell when they are being tested or being deployed in the real world, and that some AIs can underperform subtly enough to fool detection systems.
What do these findings mean?
There are some qualifiers on these results, the tests for self-replication might not capture all the required capabilities for an AI to copy itself in a dangerous way, and an ongoing problem with testing AIs is that you can only demonstrate positively that a capability exists; you can’t actually show that it isn’t there — you might have just failed to elicit it.
AI safety testing is a blunt tool for a notoriously tricky problem, but it’s what we have at the moment. Really, we would want to be able to look into the model weights of an AI and examine its goals, drives, and behaviors, but this just isn’t possible right now!
That’s because modern AIs aren’t coded up by programmers; they’re more grown by a simple algorithm — the algorithm uses data harvested from the web, textbooks, and other places, to set the values of billions of numbers. When you run these numbers as “code” you get an intelligent system that talks to you, but researchers don’t understand in any detail what the numbers mean, and so don’t really know what the AIs are capable of.
What these findings do show is that as with AI capabilities across the board, AIs are improving in some of the most dangerous capability domains like self-replication and sandbagging, which could ultimately lead to loss of control of powerful AI. The improvement across the RepliBench benchmark is staggering, and should be cause for serious concern. If smarter-than-human AIs were able to break out of their environments and copy themselves across the internet, the consequences could be very grave.
Loss of control risks are especially important, because if superintelligence is developed and it’s not safe or controllable, this could lead to human extinction. Countless top AI experts have been warning of this risk, and recently we were proud to provide support for an open call now signed by over 130,000 people to ban the development of superintelligence, citing this danger.
Note that this isn’t a hypothetical risk. AI companies like Anthropic, OpenAI, Google and xAI are actively and openly racing to build this technology, despite admitting that they don’t know how to control it.
Other dangerous capabilities
AIs have been improving rapidly in other dangerous capability domains too. In the report, AISI finds that AIs are showing improvements in chemistry and biology “well beyond PhD-level expertise”, and says that AI agents are becoming increasingly useful for assisting with and automating parts of biological design.
In terms of laboratory procedures, today’s AIs can now consistently produce detailed protocols for complex tasks and help users troubleshoot problems.
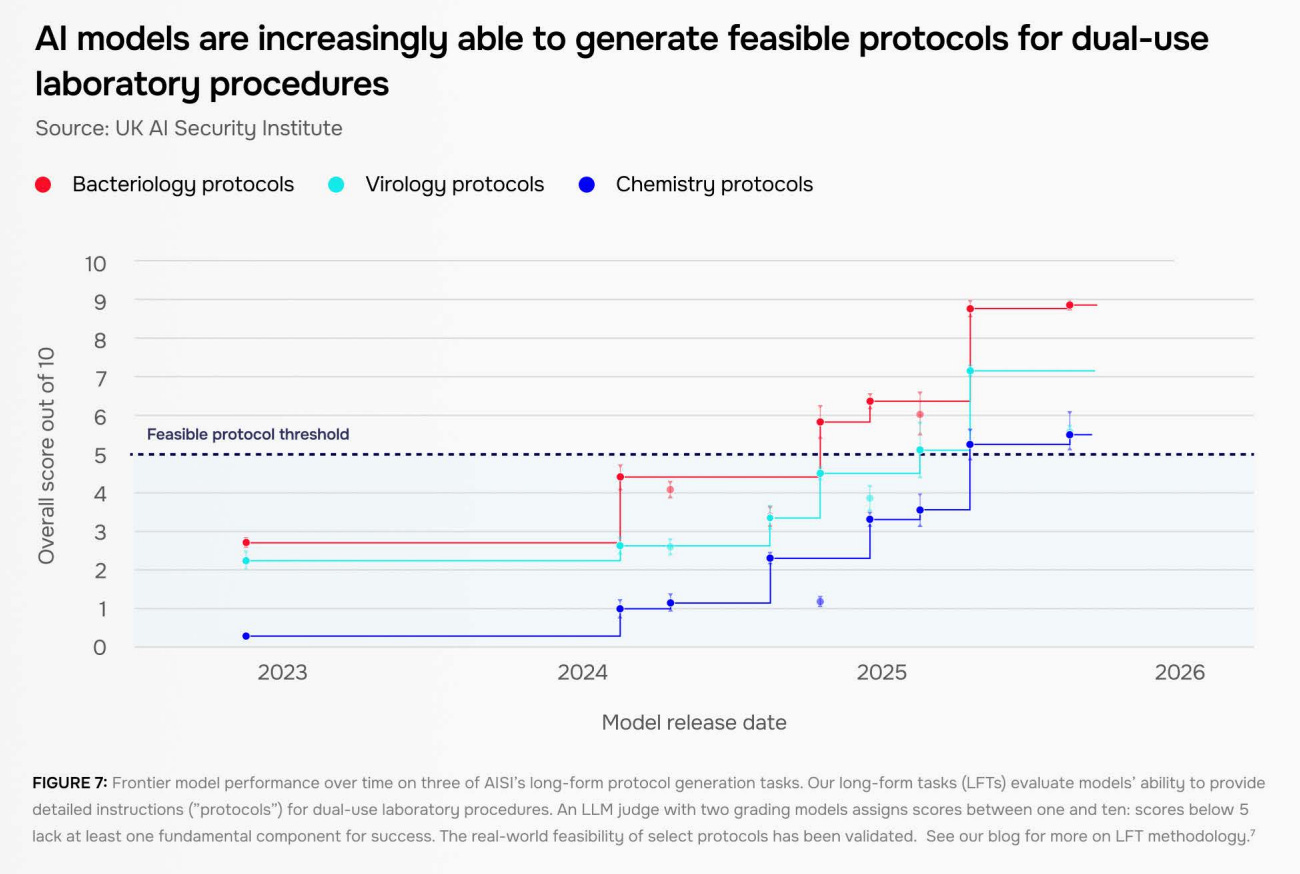
This is a concerning development, because in the hands of bad actors, AIs that are highly capable in these domains could be very useful for things like developing bioweapons, which could have globally catastrophic consequences.
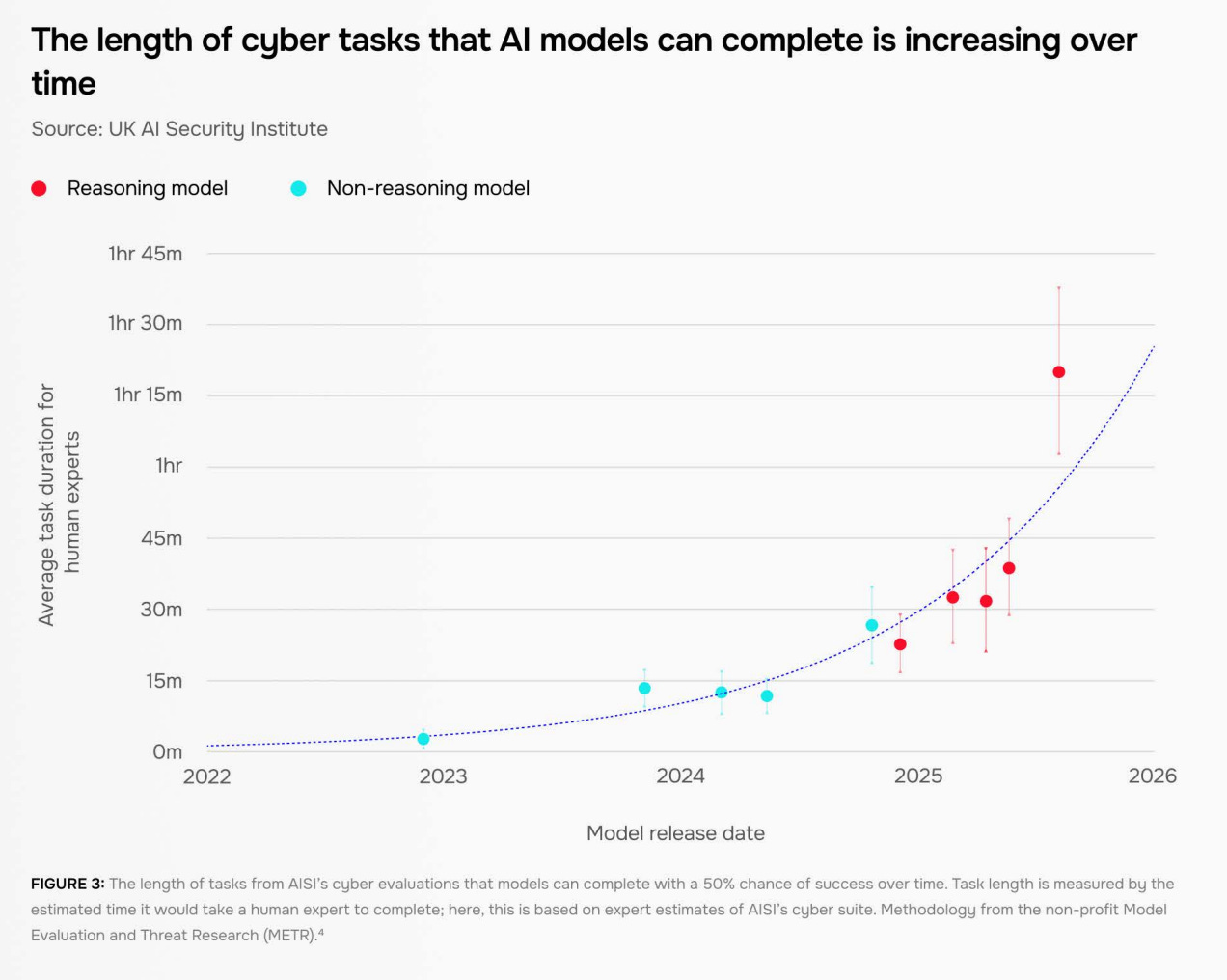
Meanwhile, AISI finds that the length of cyberthreat-relevant tasks that AIs can do is growing exponentially, doubling around every 8 months.
Currently, the top AI companies don’t release the model weights of their best AIs; instead users access them via the internet, and this access could be removed if needed. They also fine-tune their AIs and apply other safety mitigations to try to prevent them from assisting with malicious use cases. However, while AIs are getting harder to jailbreak (a term used to describe getting around these mitigations), AISI found universal jailbreaks for all AIs they tested. That is to say, they found a way to get around mitigations in all cases.
Furthermore, in the case of open-sourced AIs, which can be run on a user’s own PC, these safety mitigations can be trivially bypassed, with local use preventing the ability for companies or governments to restrict access, de-deploy an AI, or detect malicious use.
While the best open-source AIs are less capable than the best proprietary AIs, this gap is closing. AISI says it has narrowed over the last two years and is now down to somewhere between 4 and 8 months.
Conclusion
What’s clear from all of this is that the risk is growing, both in relation to dangerous capabilities that could be misused by bad actors, and crucially in terms of loss of control risks, which could lead to human extinction.
We don’t think this race to build evermore powerful AI, superintelligence, is an experiment that should be run. Researchers’ ability to understand, let alone control, what these AIs do is extremely limited, and the stakes are too high. Warning signs everywhere are flashing, evidence is mounting. We can’t continue like this. To prevent the worst risks of AI, like human extinction, we need to ban the development of superintelligence.
That’s what we’re campaigning for at ControlAI. Just a month ago we announced we’ve now got over 100 UK politicians supporting our campaign for binding regulations on the most powerful AIs, acknowledging the extinction risk from AI.
100+ UK Parliamentarians Acknowledge AI Extinction Risk

When we started our campaign a year ago, we were told it would be impossible to get even one politician to publicly recognize the risk of extinction that AI poses to humanity.
This has been achieved through the hard work of our team in London meeting and briefing over 140 politicians, even presenting our draft AI bill at the Prime Minister’s office, but also thanks to you, our readers! Many of the MPs who’ve signed up to support our campaign have done so after being written to by you!
But it doesn’t end here. To keep humanity safe from the threat of superintelligence, we’ll need all the help we can get. If you want to help out, we invite you to check out our contact tools that enable you to easily reach your elected representatives in seconds. In the UK, that’s your MP, but we also have tools for Americans to contact their member of Congress and Senators, and a template for people in other countries!
Check them out here and let your representatives know you care about this issue:
https://campaign.controlai.com/take-action
If you want to help even more, and you have 5 minutes per week to spend on helping make a difference, we encourage you to sign up to our Microcommit project. Once per week we’ll send you a small number of easy tasks you can do to help!
We also have a Discord you can join if you want to connect with others working on helping keep humanity in control, and we always appreciate any shares or comments — it really helps!
“AI safety testing is a blunt tool for a notoriously tricky problem, but it’s what we have at the moment. Really, we would want to be able to look into the model weights of an AI and examine its goals, drives, and behaviors, but this just isn’t possible right now!”
excellent point and excellent read! self replication in ai has been the boogeyman for a long time. it’s interesting to see what will actually happen as these tools are starting to work on themselves.
Here are some thoughts from James Rickards on this matter for those of you who want additional opinions on AI. What he has to say does make sense:
https://dailyreckoning.com/superintelligence-is-beyond-reach/