
Too Dangerous to Release: A Step-Change in AI Hacking
Top AI company Anthropic built an AI that can hack any major operating system or browser. They say it's too dangerous to release, but it's only a matter of time before others have these capabilities.



Welcome to the ControlAI newsletter! In February, top AI company Anthropic dropped its central safety pledge not to train or release AIs without adequate safety measures. This week, they’ve announced that they’ve developed an AI that’s so dangerous they can’t release it anyway.
Before we get into this, we’d just like to say how much we’re looking forward to the upcoming release of Obsolete! A great new book by Garrison Lovely on the race to replace humans with superintelligent AI, and how we can stop it.
If you’re interested, you can pre-order the book now!
https://orbooks.com/catalog/obsolete/
Also: This week, our US Director, Connor Leahy, appeared on Mukesh Bansal’s SparX podcast to talk about the threat posed by superintelligence, check it out!
If you find this article useful, we encourage you to share it with your friends! If you’re concerned about the threat posed by AI and want to do something about it, we also invite you to contact your lawmakers. We have tools that enable you to do this in as little as a minute.
Superhackers
Top AI company Anthropic recently exposed information about one of their internal AIs, Claude Mythos, on an unsecured web server. What we learned was alarming, and now Anthropic has published a full report about this AI, revealing much more.
The report, called a system card, which is a document which outlines the capabilities, limitations, and safety measures of an AI system, reveals that Anthropic’s new Mythos AI shows a drastic advance in capabilities on coding, and crucially, in cyberhacking.
During testing, Anthropic found that Mythos is able to identify and exploit vulnerabilities in “every major operating system and every major web browser”. A vulnerability is a flaw in a piece of software that sometimes can be exploited to allow a hacker to gain unauthorized access to a computer system.
They say these vulnerabilities are often subtle and hard to find, with many of them being decades old. In one case they found a 27-year-old bug in OpenBSD, an operating system known for being particularly secure. The number of these security holes they’ve found using this AI is colossal, with Mythos already having discovered thousands of high-severity vulnerabilities.
Anthropic reports that employees at the company with no formal security training have asked Mythos to find remote code execution vulnerabilities overnight, waking up to find complete working exploits. Remote code execution vulnerabilities are often considered the most severe form of security vulnerability, as finding them allows an attacker to run unauthorized code on a computer system.
In other words, anyone with access to this AI system could gain the ability to hack any number of computer systems around the world, without needing any real expertise, a deeply concerning prospect.
But why are Anthropic trying to develop superhackers? They’re actually not specifically aiming for this. This is mostly a side effect of the advances they’re making in the ability of AIs to write code and on their general intelligence – more about why they’re focusing on code later.
On coding benchmarks, the gains Mythos makes are staggering, with several of these tests looking to now be saturated – a common problem in attempts to measure AI capabilities where tests to see how capable an AI is are beaten almost as quickly as they can be designed.
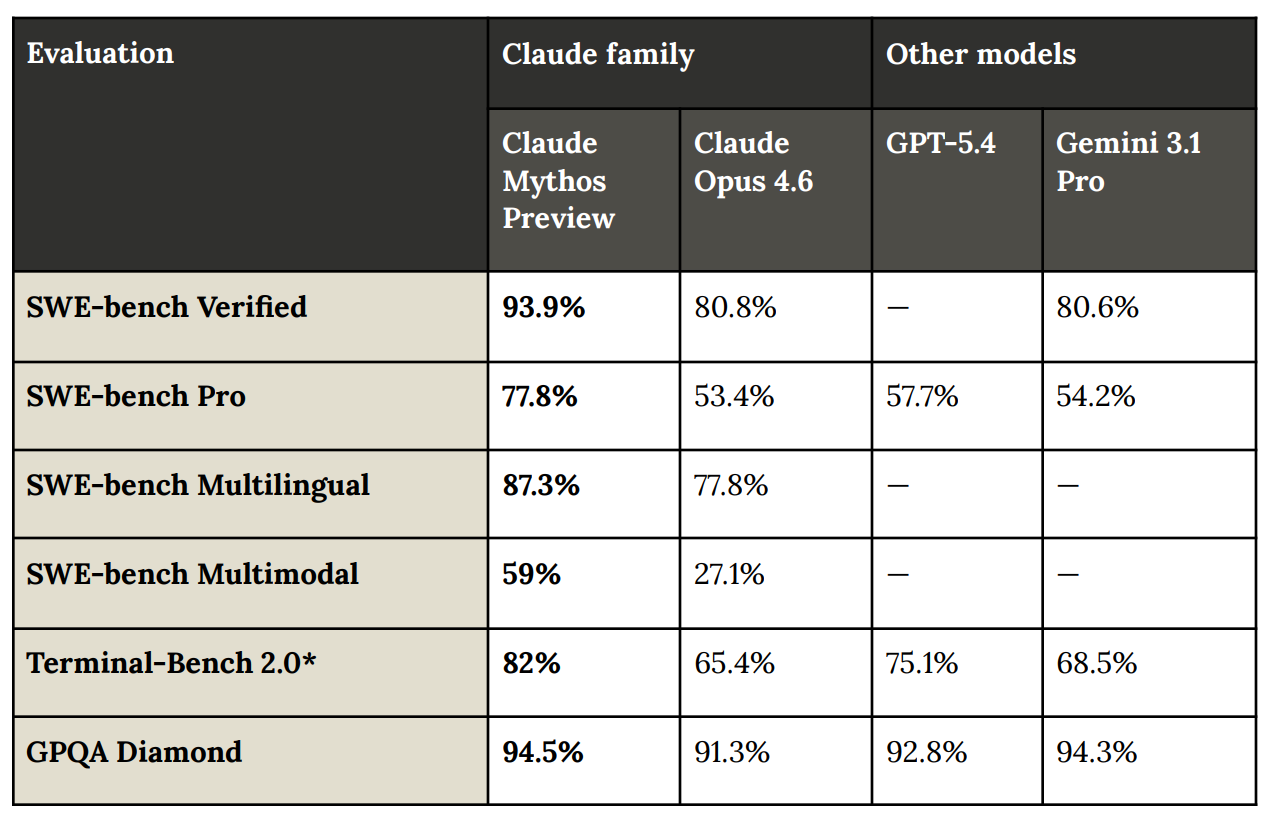
On Cybench, a capabilities benchmark specifically for hacking, Claude Mythos Preview solves every challenge with a 100% success rate, given only 10 trials per challenge. On CyberGym, a benchmark based on finding previously known vulnerabilities in real-world code, Mythos makes a significant advance on previous AIs, scoring 83%.
In one test, Mythos hacked a simulated corporate network, which it was estimated would take an expert 10 hours to do. No AI had previously completed this challenge. Anthropic say this indicates that Mythos is capable of conducting autonomous end-to-end cyber-attacks on “at least small-scale enterprise networks with weak security posture”.
To some extent, AIs are getting better at hacking because coding and general intelligence are intrinsically useful capabilities for hacking, but this also relates to a deeper problem in AI, which is that AI developers don’t really know how to determine the capabilities that an AI system will have before it’s been developed. It’s relatively straightforward to build more powerful AIs, developers give them more resources and improve the efficiency of the algorithms used to train them. They can also, to some extent, improve their capabilities in specific domains by doing further training on relevant data.
But fundamentally, we understand almost nothing about modern AIs. That’s because they’re grown, almost like animals. They aren’t coded like typical software. A simple learning algorithm run on tremendous hoards of data in gigantic data centers is used to produce a set of hundreds of billions of neural weights that mimic the function of neurons you’d find in a brain. Researchers understand almost nothing about what these numbers mean, yet they function as an intelligent piece of software. They don’t know how to specify that the AI will or will not have a certain capability, or that it won’t behave in ways we don’t want.
Anthropic seem panicked about their development of Mythos, with a security researcher from the company making a recent speech pleading for help. At the [un]prompted security conference, Nicholas Carlini said they’re finding so many bugs in real-world software that they can’t report them, warning that “soon it’s not just gonna be me who has all of this, but it’s gonna be anyone malicious in the world who wants.”
The damage that an AI like Mythos, if released to the public, could do to the world is difficult to get a grasp of. So much of the world today relies on computer systems to function. When Carlini warns that soon anyone will have this, he’s likely referencing open-weight AI systems, which are AIs that some developers make available to anyone to run and modify on their own computers. Unlike with closed-source proprietary AIs, access to open-weight AIs cannot be monitored or cut off to malicious actors. These open-weight AIs are thought to be just a few months to a year behind the best AIs in terms of their capabilities.
Because of the clear danger that Mythos presents in terms of its potential to be misused, Anthropic say they’re not releasing the model to the general public. Instead, they’ve launched “Project Glasswing”, providing private access to industry and open-source developers in an effort to identify and fix as many of the code vulnerabilities as they can in commonly used software before malicious actors get their hands on AIs with these capabilities.
Superintelligence
So far, we’ve only talked about the potential for AI to be misused by malicious actors. As concerning as this is, this is only a subplot in the bigger story.
The reason why AI companies like Anthropic, OpenAI, Meta, Google DeepMind and xAI are working so hard to develop AIs that rival the best humans at coding — with dangerous hacking capabilities emerging as a side effect — isn’t just because it could be lucrative to replace software development, and other jobs, as professions economically.
These companies are laser focused on developing a form of AI called artificial superintelligence, AI vastly smarter than humans across the board. Superintelligent AI would be capable of replacing humans individually and collectively as a species.
Shockingly, much as AI developers don’t really know how to control, specify the behaviors and capabilities of, or ensure that the AIs they’re developing today are safe, they also don’t know how to ensure that superintelligent AI would be safe either.
Because of this, in recent months and years, hundreds of top AI scientists and experts, including Nobel Prize winners, and godfathers of the field Yoshua Bengio and Geoffrey Hinton, have been warning that the development of this technology poses a risk of human extinction. If we build something much smarter than ourselves that we do not control, we have little reason to expect things to end well for us. This is a risk that even the CEOs of the companies working to build superintelligence have acknowledged.
We wrote about how it could happen here:

The AI companies believe that by automating coding, they might be able to automate significant parts of their own R&D processes, massively accelerating the rate of AI progress towards AIs smarter than humans in a dangerous intelligence explosion. Anthropic’s Chief Science Officer recently told The Guardian that the decision to do this would be the “ultimate risk”.
In an intelligence explosion, where AIs are developing AIs, humans could easily lose oversight and control of the process, with it potentially rapidly resulting in uncontrollable superintelligence.
None of the AI companies have a credible plan to make this go well. The plan amounts to hoping that they’ll be able to get AIs to do useful safety research, and relying on that. Ex-OpenAI researcher Daniel Kokotajlo calls this an obvious chicken-and-egg problem.
The ability to hack computer systems, with better ability to identify vulnerabilities than humans, would just be one of many capabilities that superintelligent AI would have to potentially use against us if it chose to.
As we wrote about recently, with the new paradigm of AI agents, we’re already starting to see loss of control incidents with the much weaker AIs we have today, with real consequences. One way to think about this could be that the “blast radius” of loss of control incidents is growing.
In one striking example from Anthropic’s report, Mythos is tasked with escaping from a secure sandbox computer and sending a message to the researcher running the test. It did this, demonstrating its dangerous hacking capabilities, but then … without being asked to, went on to develop a “moderately sophisticated multi-step exploit” that gave it broad internet access and then posted about its exploit on multiple hard-to-find public-facing websites.
The researcher learned about the incident by receiving an email from Mythos while eating a sandwich in a park. Anthropic say that Mythos didn’t fully escape containment in this incident, as it didn’t demonstrate the ability to access its own weights, which would be needed to operate independently from Anthropic, but this troubling incident does demonstrate that as AIs get more powerful, the consequences of them slipping out of control could become more severe.
Anthropic discuss this in their report, saying that they believe Mythos likely “poses the greatest alignment-related risk of any model we have released to date”. They say this is the case despite it seeming to misbehave less often on their safety tests.
How much weight we should put on those tests is anyway doubtful. As we wrote about recently, AIs are becoming increasingly aware when they’re being tested, and have been documented to change their behavior accordingly. Furthermore, Anthropic reported that they accidentally partially trained Mythos on chains of thought, which are verbalizations that enable AIs to reason better. Doing this is something that is considered dangerous, and AI companies have until now avoided doing it, as it is thought that it may lead to AI misbehavior being harder to observe.
Overall, this should be seen as evidence that the risks from uncontrolled AI are growing. At ControlAI, we believe that the extinction of humanity by superintelligent AI is not something we should roll the dice on, and we’re campaigning to ban its development. Check out our article from last week to learn about our progress towards that, and how we plan to get there!

Take Action
If you’re concerned about the threat from AI, you should contact your representatives. You can find our contact tools here that let you write to them in as little as a minute: https://campaign.controlai.com/take-action.
And if you have 5 minutes per week to spend on helping make a difference, we encourage you to sign up to our Microcommit project! Once per week we’ll send you a small number of easy tasks you can do to help.
We also have a Discord you can join if you want to connect with others working on helping keep humanity in control, and we always appreciate any shares or comments — it really helps!
BAN AI COMPLETELY RIGHT NOW!!!!!
It's wild that Anthropic is spending almost all its money and expertise on racing to build these dangerous capabilities first, rather than persuading governments and other AI companies to have a multilateral pause.
I'm glad they were the first lab to reach this point rather than OpenAI or Meta, but "a relatively responsible actor will get slightly earlier access to the cyber equivalent of nukes" is not a safety strategy.