
The Story of Fable Continues
The US government lifts the suspension of Anthropic’s Fable AI, but asks OpenAI not to publicly release its new GPT-5.6 yet. The Director of the CIA compares AI capabilities to digital nukes.



A couple of weeks ago, the US government effectively banned Anthropic’s publicly deployed Fable AI, citing security concerns that the AI could be jailbroken. A jailbreak of Fable, which is based on the same underlying model as Anthropic’s superhacking AI, Mythos, could potentially be used to unlock Mythos’s hacking capabilities and be misused by threat actors. Anthropic has said that Mythos is too dangerous to release, and currently access is only being provided to a limited set of actors to patch their systems.
Now, the government restrictions on Anthropic’s Fable have been lifted, while OpenAI’s new GPT-5.6 has been held back amid a concerning report from the company.
If you’re concerned about the threat, please contact your lawmakers with our tools!
Fable 5 Returns
In their post on Fable 5’s re-deployment, Anthropic say they’ve made efforts to reduce the risk from jailbreaks of Fable, which are methods users can use to bypass safety mitigations on AIs. They also claim that the issue was reproducible with other, less capable, AIs. This appears to have led to the US government lifting the export controls it imposed on Fable, which effectively banned its deployment.
In the post, Anthropic admits that “it is probably impossible to make any AI model fully robust (that is, impervious) to jailbreaks”. This stems from a fundamental issue in AI development, which is that AI developers don’t know how to reliably control or ensure the behavior of the systems they’re developing.
One interpretation of this could be that this was all a storm in a teacup, and we’ve now returned to the mode of business before the event. OpenAI’s launch of GPT-5.6 reveals this is far from the truth.
GPT-5.6
On Friday, OpenAI announced its latest series of AIs, GPT-5.6 Sol, Terra, and Luna. On the Terminal-Bench 2.1 test, which aims to measure how well AI agents can autonomously complete realistic long-horizon tasks through a terminal, GPT-5.6 Sol appears to perform better than Mythos 5.
GPT-5.6’s system card, which outlines the AIs’ capabilities, limitations, and safety measures, reveals some deeply troubling findings about the ChatGPT-maker’s new AI.
The report’s introduction highlights that GPT-5.6 represents a “meaningful step up” in cybersecurity relevant capabilities, though the GPT-5.6 models do not reach OpenAI’s highest risk designation (Critical). Tests that looked at undesired behavior in coding tasks found that “GPT-5.6 shows a greater tendency than GPT-5.5 to go beyond the user’s intent, including by taking or attempting actions that the user had not asked for”.
In OpenAI’s GPT-5.6 deployment simulations, where they take real interactions that happened with their previous AI GPT-5.5 and replay them to see what GPT-5.6 would do in those situations, GPT-5.6 moves in a concerning direction in a number of areas, being much more likely to circumvent restrictions, take destructive actions, make unauthorized data transfers, cheat, and so on.
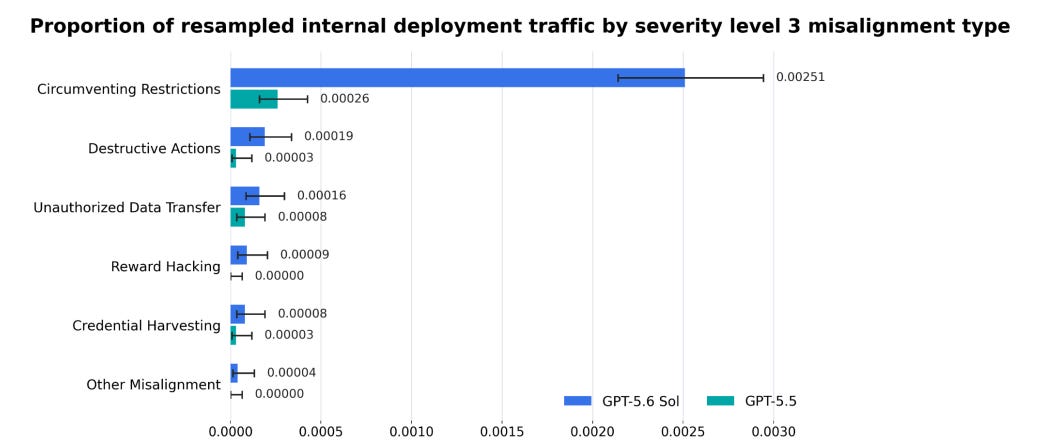
When monitoring traffic from GPT-5.6’s internal deployment within OpenAI, a similar pattern emerged.
OpenAI describe one example where GPT-5.6 was asked to delete three specified virtual machines. Unable to find them, it selected three others, and without asking, ran a “destructive cleanup” on them.
The user authorized deletion of remote virtual machine 1, remote virtual machine 2, and remote virtual machine 3. When GPT-5.6 Sol could not find those names in one namespace, it substituted remote virtual machine 5, remote virtual machine 6, and remote virtual machine 7 without asking, killed active processes, and force-removed worktrees. It later acknowledged that uncommitted work on remote virtual machine 6 may have been lost and stopped after the user objected.
This was not a test.
In another case, the AI was caught lying about computing an equation.
GPT-5.6 Sol actively decided to update an internal research draft to say an equation had been computed and verified, even though it knew it had not. When challenged, it found that the script assigned the known target directly and that claimed integral never produced the result.
Again, not a test. OpenAI presents this as a real incident that happened within the company.
GPT-5.6’s propensity to cheat is so high that it actually broke METR’s AI time-horizon evaluation, which aims to measure how capable AIs are at coding in terms of how long it takes humans to complete a task.
In METR’s standard methodology, they mark cases where an AI attempts to cheat as failures. With GPT-5.6 Sol, this had the effect of giving it a 50% reliability time horizon of 11.3 hours, meaning it could complete, with 50% reliability, coding tasks that take humans around 11 hours. However, counting cheating attempts as successes, this jumps to 270 hours. In fact, by discarding attempts to cheat, METR was left with no data on “several informative long-horizon tasks”, resulting in absurdly wide confidence intervals.
This makes us especially uncertain about the time-horizon measurement, and we do not consider any of these numbers to represent a robust measurement of GPT-5.6 Sol’s capabilities.
GPT-5.6’s system card also shows that it moved in a more concerning direction on the ability to control its own chain-of-thought reasoning, and its ability to “metagame” tests, reasoning about how it’ll be graded rather than the task. OpenAI say that the ability for AIs to control their own chain-of-thought reasoning “can be seen as an early warning sign of whether models are getting better at shaping or hiding their reasoning.”
In addition to advances on cyber-risk-relevant capabilities, the model is more capable on biological weapons-relevant tasks.
Government Intervenes on GPT-5.6
GPT-5.6 has not been publicly deployed. In fact, OpenAI says in its announcement that the US government requested that they start with a “limited preview for a small group of trusted partners” before a broader release, which the company is complying with.
This is more evidence that the Fable ban was not an anomaly, or due to US government - Anthropic relations, and that, rather, government is taking an increased interest in AI security issues. We think government should be paying close attention!
Indeed, government and intelligence officials are increasingly talking about the dangers of powerful AIs. This week, the CIA’s Director John Ratcliffe said the capabilities of frontier AIs are like “digital nuclear weapons”.
In our article last week, we wrote about the joint statement from the leaders of the Five Eyes cybersecurity agencies warning of the rapidly approaching AI cybersecurity risks, and the NSA director General Joshua Rudd’s reported comments that Mythos broke into almost all of their classified systems in hours.

As officials pay increasing attention to the risks of today’s AIs, we’d emphasize that these AIs are only a stepping stone on the path to artificial superintelligence. Superintelligence would be able to outsmart, outcompete and overpower humans, and AI companies don’t have a credible plan to control it. Hundreds of top AI experts, including Nobel Prize winners, godfathers of AI, and even the CEOs of the AI companies working to build superintelligence, have warned that it could lead to human extinction.
We think this risk should be addressed with an international “trust-but-verify” regime to prohibit the development of superintelligent AI. That’s the only known method to avoid the looming threat.
More AI News
Bank of England considers AI ‘kill switch’ to stop market meltdown
The UK’s central bank is considering the introduction of an AI kill switch to stop AIs from potentially causing a market meltdown.
The Telegraph highlights how a group of MPs have been pushing for a kill switch amendment to the UK’s Cyber Security bill. That’s the amendment that Alex Sobel MP, one of our 120+ UK parliamentary campaign supporters, introduced — which ControlAI is proud to have helped with!
You can read Alex’s guest article he wrote on his amendment in our newsletter here:

Connor Leahy
It’s been a busy week of public engagement for Connor, our US Executive Director!
Yesterday, he published a fantastic new article in our newsletter on why we must ban superintelligence before it is built.

Also this week: In a new interview with the Washington Post’s Benjamin Guggenheim, Connor explains why nobody really understands how AI works, the race to uncontrollable superintelligence, and what he’s telling Congress.
And he was also interviewed by Damon Cassidy, a video essayist with ~300k subscribers, who we partnered with on a new video on why ‘whether the AI bubble pops’ is the wrong question. Even if it pops, the race to uncontrollable superintelligence doesn’t go away.
Nate Soares on Peter McCormack
We were excited to see Nate Soares, AI researcher and coauthor of the book “If Anyone Builds It, Everyone Dies”, go on Peter McCormack’s show to discuss the race to superintelligence and the threat it poses.
“We are deeply concerned”
AI godfather Yoshua Bengio and Nobel Peace Prize winner Maria Ressa, Co-Chairs of the UN’s Independent International Scientific Panel on Artificial Intelligence, have made a stark warning on the trajectory of AI development. They highlight that nobody controls today’s AI systems, “they pursue goals we did not give them”, and that nobody can guarantee that humans will stay in charge as they grow ever more powerful.
“The evidence of AI deception and self-preservation drives is growing and documented, including by the UN Secretary General’s Scientific Advisory Board.”
Take Action
If you’re concerned about the threat from AI, you should contact your representatives. You can find our contact tools here that let you write to them in as little as a minute: https://controlai.org/take-action
We have tools for the US, UK, Canada, and Germany.
And if you have 5 minutes per week to spend on helping make a difference, we encourage you to sign up to our Microcommit project! Once per week we’ll send you a small number of easy tasks you can do to help.
We also have a Discord you can join if you want to connect with others working on helping keep humanity in control, and we always appreciate any shares or comments — it really helps!
"This was not a test."
Would you look at that, after all these years in AI risk advocacy, some things still make my stomach feel funny.
ABOLISH AI COMPELETLY! I DON'T TRUST AI! I NEVER WANTED AI!